




L’intelligenza artificiale è ormai considerata la tecnologia computazionale abilitante per l’innovazione tecnologica dei prossimi anni. Internet of Things (IoT) fa già ampio utilizzo di paradigmi computazionali Deep Learning per offrire servizi di ricerca di informazioni in rete o per il riconoscimento di informazioni audio-visuali, mentre la ormai imminente Internet of Everythings (IoE) si sta preparando per gestire e fornire servizi che trattano i dati di miliardi di sensori connessi in rete
I paradigmi computazionali tradizionali – Deep Learning/Machine Learning e – le Reti Neurali Artificiali (ANN) sono più semplici da progettare, ma computazionalmente sono più intensivi e richiedono un’enorme quantità di dati per essere configurati; ciò rappresenta il limite al loro impiego.
Tale limite al presente viene superato in termini di sovradimensionamento computazionale, basato sull’uso spropositato della potenza di calcolo fornita dalla rete (cloud computing), in evidente contraddizione della tendenza verso l’embedded computing che tende a spostare verso la periferia della rete il processo di elaborazione (Edge Computing) allo scopo di ridurre la complessità e i costi (infrastrutturali) delle applicazioni.
La tecnologia abilitante dell’Edge Computing è quella delle MicroControl Units (MCUs) che, negli ultimi anni, sono diventate sempre più potenti dal punto di vista dell’elaborazione dati, a bassissimo consumo energetico, di piccolissime dimensioni e bassissimo costo (cioè ultra-embedded), ma i paradigmi Deep Learning non sono concepiti per essere eseguiti dalle MCU, data la complessità computazionale e gli elevati requisiti di memoria richiesti.
Ecco dunque che l’esigenza di far eseguire processi inferenziali come quelli dell’intelligenza artificiale sta facendo pressione sul mondo dei chip per sviluppare nuovi processori più efficienti in quanto elaborazione dati e con maggiori capacità di memoria. Varie sono le soluzioni attualmente a disposizione di chi deve sviluppare applicazioni di machine learning: dall’architettura tradizionale del processore basato sulla CPU, nello specifico MPU e GPU come per esempio quella di NVIDIA GPU GM206, un processore a 28 nm di 228 mm² e ben 2940 milioni di transistor che implementa 1024 core, capace di 2 GB di memoria e capace di trattare dati in strutture matriciali e di eseguire in maniera efficiente le operazioni di calcolo richieste dalla convoluzione, tipica operazione dell’elaborazione grafica e di paradigmi inferenziali molto popolari dell’intelligenza artificiale come le reti neurali convolutive (CNN).
Alla soluzione di sviluppo basata sull’architettura computazionale software programmabile delle GPU si contrappone quella delle architetture hardware programmabili basate sulla tecnologia FPGA ed eFPGA, soluzione che garantisce una corrispondenza tra architettura computazionale (parallelismo esecutivo, unità aritmetiche ottimizzate di moltiplicazione-accumulo MAC, unità di comunicazione ad elevata frequenza di trasferimento dei dati) ed architettura inferenziale ANN.
Una ulteriore soluzione di sviluppo è quella dell’estensione e potenziamento dell’architettura MCU nella direzione del supporto allo sviluppo delle applicazioni di Machine Learning, come nel caso del Ethos N77 di ARM, un processore NPU ottimizzato per il Machine Learning (Convolutional Neural Networks, Recurrent Neural Networks), dotato di un MAC engine (Multiply Accumulate Engine 2048 MAC 8x8), di precisione mista (8-16 bit), multicore (supporta otto processori in modalità cluster, fino a 64 core con la tecnologia mesh CoreLink), accesso efficiente alla memoria, elevata potenza computazionale (4 TOP/s a 1 GHz), memoria embedded 1-4 MB.
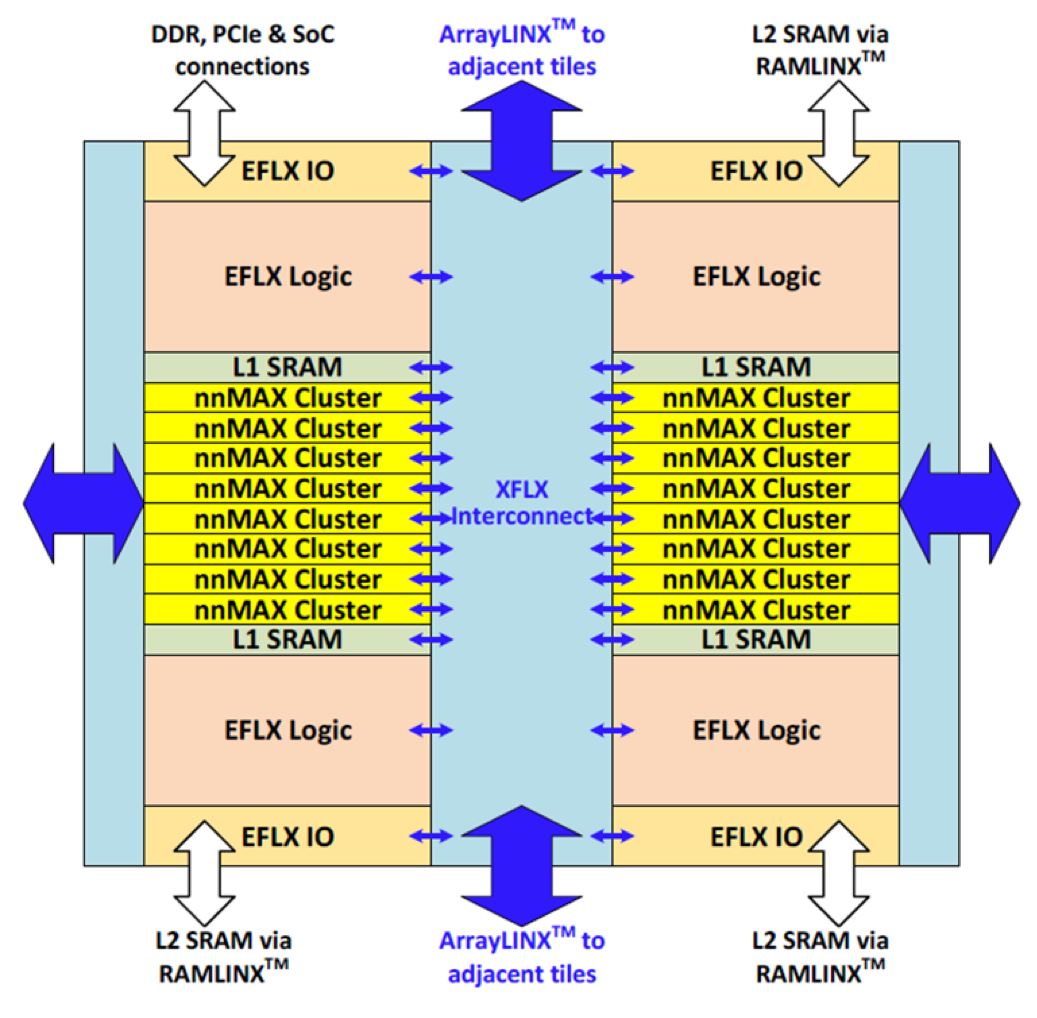
Soluzioni come le GPU, le FPGA o le MPU, pur essendo relativamente soddisfacenti dal punto di vista computazionale, non soddisfano i requisiti di elevato embedding del target applicativo del machine learning. Ecco dunque emergere la soluzione degli Application Specific Processors (ASPs). l’AI processor Infer X X1 che ha sviluppato FlexLogic è un inference chip che implementa l’INT8 Winograd acceleration, una ottimizzazione computazionale che aumenta la precisione e riduce la il costo computazionale di fondamentali algoritmi utilizzati nell’apprendimento automatico dell’AI come la trasformata veloce di Fourier (FFT). Infer X X1 integra numerosi nnMAX Cluster (gli nnMAX cluster sono unità processore dotate di unità computazionali ottimizzate per il calcolo inferenziale, tra cui le MAC 1024 DSP a 1067 GHz per ogni nnMAX). Gli nnMAx sono integrati nel chip in disposizione ad array con un meccanismo di interconnessione (XFLX interconnect) che consente di ottenere la configurazione computazionale utile al paradigma inferenziale che deve essere implementato. Il chip integra anche una RAM che consente la memorizzazione ottimale dei pesi che configurano la conoscenza del paradigma inferenziale dopo la fase di apprendimento, specificamente per le reti Deep Neural Network (DNN).
Machine learning: verso i paradigmi brain-inspired
Per quanto i chip come Infer X X1 consentano di ottenere prestazioni computazionali in periferia (Edge) paragonabili a quelle del data center della rete con gli ovvi vantaggi dell’elevato livello di embedding, la soluzione alla complessità computazionale del deep learning basato sui paradigmi inferenziali di prima generazione non può essere esclusivamente di natura hardware, ma richiede il passaggio a nuovi paradigmi inferenziali cosiddetti brain-inspired, ciò quelli che traggono ispirazione diretta dai meccanismi cerebrali naturali, particolarmente efficienti relativamente alla fase di apprendimento (learning) e a quella di inferenza, con caratteristiche uniche come l’apprendimento on-line ed evolutivo e l’estrazione della conoscenza (features) direttamente dai dati.
I più rappresentativi di tali paradigmi brain-inspired sono quelli evolutivi, in particolare le Evolving Spiking Neural Networks (ESNNs. In generale, le SSN sono paradigmi di rete neurale che implementano il neurone biologico emulando i segnali naturali del sistema nervoso (spikes) e il meccanismo di elaborazione degli spikes del neurone naturale (meccanismo d’azione). La peculiarità delle SSN sta nella modalità di elaborazione interna dell’informazione, cioè come sequenza di spikes (impulsi). In particolare, le SNN evolving, le ESSN, hanno neuroni che vengono creati (evolvono) e si interconnettono in modalità incrementale allo scopo di catturare raggruppamenti (cluster) e caratteristiche (pattern) dai dati in arrivo, esprimendo in tal modo un comportamento adattivo. Questo comportamento e connotazione delle ESNN consente a queste di eseguire l’apprendimento in modo veloce (anche in un solo passo), mentre le ANN tradizionali richiedono cicli di apprendimento molto lunghi e computazionalmente onerosi.
L’implementazione hardware delle SNN evidenzia connotazioni embedded particolarmente interessanti relativamente alle dimensioni e all’efficienza energetica. Una prima implementazione è stata Akida di BrainChip, un System-on-Chip (SoC) che replica l’architettura delle SNN (spiking neuron con meccanismo d’azione e sinapsi) integrando 1,2 milioni di neuroni e 10 miliardi di sinapsi. Akida di BrainChip è finalizzato all’accelerazione computazionale in applicazioni come i Dynamic Vision Sensor (DVS), i LIDAR, l’audio processing, e il signal processing. Akida consiste di un array di neuroni (Flexible Neuron Fabric) affiancato da una serie di moduli che consentono di eseguire in modalità hardware le operazioni previste dal paradigma Spiking Neural Network, come la conversione in spikes dei segnali forniti da sensori sotto forma di dati campionati. Il SoC integra anche un processore M-Class dotato di unità floating point (FPU) e Digital Signal Processing (DSP), utile anche ad eseguire software di sistema e a controllare il flusso dei dati.
Successivamente Intel ha annunciato nel 2017 un chip neuromorfo in tecnologia a 14 nm, il LoiHi, un sistema di 128 core ad architettura ottimizzata per l’esecuzione del paradigma SNN con un totale di 130.000 neuroni, ognuno capace di comunicare con altre migliaia di neuroni simili. Il meccanismo di apprendimento è embedded, on-line e continua a sovraperformare le prestazioni dei paradigmi ANN tradizionali come le reti neuronali convolutive (CNN) e i relativi meccanismi di apprendimento (backpropagation).






 si sta preparando per gestire e fornire servizi che trattano i dati di miliardi di sensori connessi in rete){kind=link}