




Il primo di tre articoli di Analog Device dedicati alle reti neurali convoluzionali, quelle reti che consentono il riconoscimento di schemi e la classificazione di oggetti contenuti nei dati di ingresso. Insomma, quello che sta alla base dell’apprendimento della più avanzata intelligenza artificiale.
Il mondo dell'intelligenza artificiale è in rapida evoluzione e sta consentendo di realizzare un numero sempre più grande di applicazioni che in precedenza erano irraggiungibili o molto difficili da implementare. Questa serie di articoli spiega le reti neurali convoluzionali (CNN, Convolutional Neural Networks) e la loro importanza nell'apprendimento automatico all'interno dei sistemi di AI. Le CNN sono strumenti potenti per estrarre caratteristiche da dati complessi. Ciò include, ad esempio, il riconoscimento di schemi complessi in segnali audio o immagini. Questo articolo illustra i vantaggi delle CNN rispetto alla programmazione lineare classica. Un articolo successivo, "Addestramento delle reti neurali convoluzionali: Cos'è il Machine Learning? - Parte 2" illustrerà come vengono addestrati i modelli CNN. La terza parte esaminerà un caso d'uso specifico per testare il modello con l’utilizzo di un microcontrollore AI dedicato.
Cosa sono le reti neurali convoluzionali?
Le reti neurali sono sistemi che permettono all'intelligenza artificiale di comprendere meglio i dati, consentendole di risolvere problemi complessi. Sebbene esistano numerosi tipi di reti, questa serie di articoli si concentrerà esclusivamente sulle reti neurali convoluzionali (CNN). Le principali aree di applicazione delle CNN sono il riconoscimento di schemi e la classificazione di oggetti contenuti nei dati di ingresso. Le CNN sono un tipo di rete neurale artificiale utilizzata nel deep learning. Tali reti sono composte da un livello di ingresso, diversi livelli convoluzionali e un livello di uscita. I livelli convoluzionali sono i componenti più importanti, poiché utilizzano un insieme di coefficienti e filtri unico che permette alla rete di estrarre caratteristiche dai dati in ingresso. I dati possono presentarsi in molte forme diverse, come immagini, audio e testo. Questo processo di estrazione delle caratteristiche consente alla CNN di identificare schemi nei dati. Estraendo le caratteristiche dai dati, le CNN consentono agli ingegneri di creare applicazioni più efficaci ed efficienti. Per comprendere meglio le CNN, discuteremo prima la programmazione lineare classica.
L'esecuzione di programmi lineari nell’ingegneria del controllo classica
Nell'ingegneria del controllo, il processo consiste nel leggere i dati da uno o più sensori, elaborarli, rispondere in base a regole e monitorare o inoltrare i risultati. Ad esempio, un regolatore di temperaturaesegue una misura al secondo attraverso un microcontrollore (MCU) che legge i dati dal sensore di temperatira. I valori ricavati da questo sensore servono come dati di ingresso per il sistema di controllo a loop chiuso e vengono confrontati ciclicamente con la temperatura di riferimento. Questo è un esempio di esecuzione lineare, eseguita dall'MCU. Questa tecnica fornisce risultati definitivi, basati su una serie di valori pre-programmati e reali. Al contrario, nel funzionamento dei sistemi di intelligenza artificiale le probabilità svolgono un ruolo importante.
Elaborazione di schemi e segnali complessi
Esistono anche numerose applicazioni che lavorano con dati di ingresso che devono essere prima interpretati da un sistema di riconoscimento di pattern o schemi. Questo riconoscimento può essere applicato a diverse strutture di dati. Nei nostri esempi, ci limitiamo a quelle monodimensionali e bidimensionali. Per citare alcuni esempi: segnali audio, elettrocardiogrammi (ECG), fotopletismografi (PPG), vibrazioni per i dati monodimensionali e immagini, immagini termiche e grafici a cascata per i dati bidimensionali.
Nel riconoscimento di schemi utilizzato per i casi citati, la conversione dell'applicazione in codice classico per l'MCU è estremamente difficile. Un esempio è il riconoscimento di un oggetto (ad esempio, un gatto) in un'immagine. In questo caso, non fa differenza se l'immagine da analizzare proviene da una registrazione precedente o è stata appena letta dal sensore della fotocamera. Il software di analisi esegue una ricerca basata su regole per trovare schemi che possano essere attribuiti a quelli di un gatto: le tipiche orecchie a punta, il naso triangolare o i baffi. Se queste caratteristiche possono essere riconosciute nell'immagine, il software segnala il rilevamento di un gatto. A questo punto sorgono alcune domande: Cosa farebbe il sistema di riconoscimento di schemi se il gatto fosse mostrato solo di spalle? Cosa succederebbe se non avesse i baffi o se avesse perso le zampe in un incidente? Nonostante l'improbabilità di queste eccezioni, il codice di riconoscimento di schemi dovrebbe controllare un gran numero di regole aggiuntive che coprono tutte le possibili anomalie. Anche nel nostro semplice esempio, le regole impostate dal software diventerebbero rapidamente numerose.
Come il Machine Learning sostituisce le regole classiche
L'idea alla base dell'AI è quella di imitare l'apprendimento umano su scala ridotta. Invece di formulare un gran numero di regole "if-then", modelliamo una macchina universale per il riconoscimento di schemi. La differenza fondamentale tra i due approcci è che l'AI, a differenza di un insieme di regole, non fornisce un risultato chiaro. Invece di dire "Ho riconosciuto un gatto nell'immagine", il Machine Learning produce il risultato "C'è una probabilità del 97,5% che l'immagine mostri un gatto. Potrebbe anche essere un leopardo (2,1%) o una tigre (0,4%)". Ciò significa che lo sviluppatore di un'applicazione di questo tipo alla fine del processo di riconoscimento di schemi deve prendere una decisione. A tal fine viene utilizzata una soglia decisionale.
Un'altra differenza è che una macchina per il riconoscimento di schemi non è dotata di regole fisse, ma viene invece addestrata. In questo processo di apprendimento, alla rete neurale viene mostrato un gran numero di immagini di gatti. Alla fine, questa rete è in grado di riconoscere in modo indipendente la presenza o meno di un gatto in un'immagine. Il punto cruciale è che il riconoscimento futuro non è limitato alle immagini di addestramento già note. Questa rete neurale deve essere mappata in una MCU.
Com’è fatta esattamente, al suo interno, una macchina per il riconoscimento di schemi?
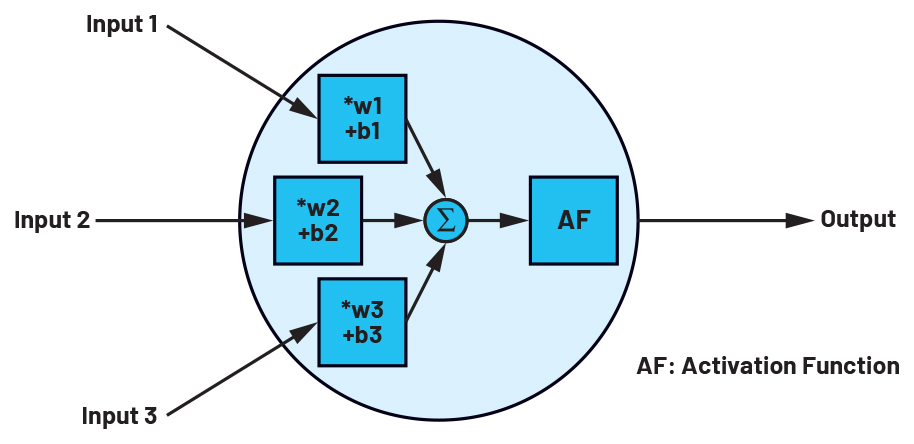
Una rete neurale nell'AI assomiglia alla sua controparte biologica nel cervello umano. Un neurone ha diversi ingressi e una sola uscita. Fondamentalmente, un neurone di questo tipo non è altro che una trasformazione lineare degli ingressi - la loro moltiplicazione per coefficienti (pesi, w) e l'aggiunta di una costante (bias, b) - seguita da una funzione non lineare fissa, nota anche come funzione di attivazione.[1] Questa funzione, in quanto unica componente non lineare della rete, serve a definire l'intervallo di valori in cui si attiva un neurone artificiale. La funzione di un neurone può essere descritta matematicamente come
 dove f = funzione di attivazione, w = peso, x = dati in ingresso e b = bias. I dati possono essere scalari, vettori o sotto forma di matrice. La Figura 1 mostra un neurone con tre ingressi e una funzione di attivazione ReLU [2]. I neuroni di una rete sono sempre disposti a livelli.
dove f = funzione di attivazione, w = peso, x = dati in ingresso e b = bias. I dati possono essere scalari, vettori o sotto forma di matrice. La Figura 1 mostra un neurone con tre ingressi e una funzione di attivazione ReLU [2]. I neuroni di una rete sono sempre disposti a livelli.
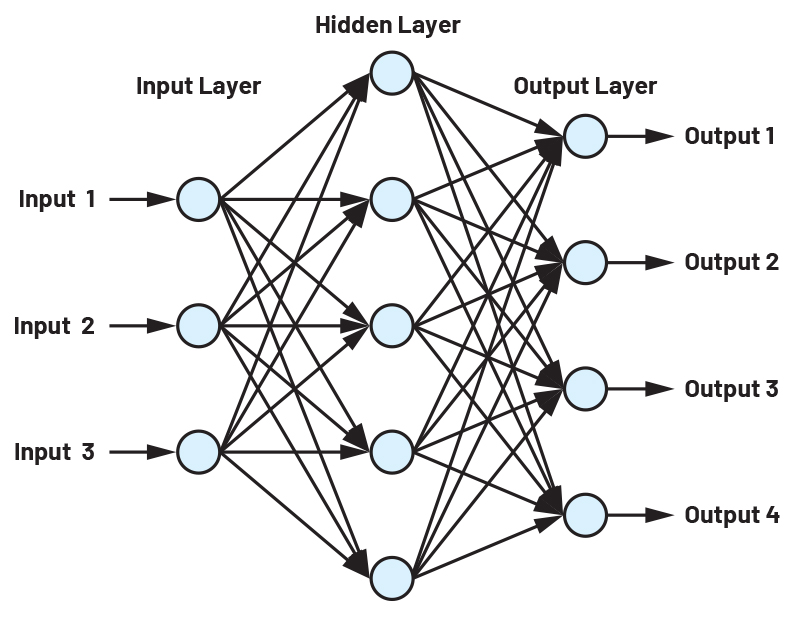
Come già detto, le CNN sono utilizzate per il riconoscimento di schemi e la classificazione di oggetti contenuti nei dati di ingresso. Le CNN sono divise in varie sezioni: un livello di ingresso, diversi livelli nascosti e un livello di uscita. Una piccola rete con tre ingressi, un livello nascosto con cinque neuroni e un livello di uscita con quattro uscite è mostrata nella Figura 2. Tutte le uscite dei neuroni sono collegate tra loro e tutte le uscite dei neuroni sono collegate a tutti gli ingressi del livello successivo. La rete mostrata nella Figura 2 non è in grado di elaborare compiti significativi e viene utilizzata solo a scopo dimostrativo. Anche in questa piccola rete, nell'equazione utilizzata per descriverla ci sono 32 bias e 32 pesi.
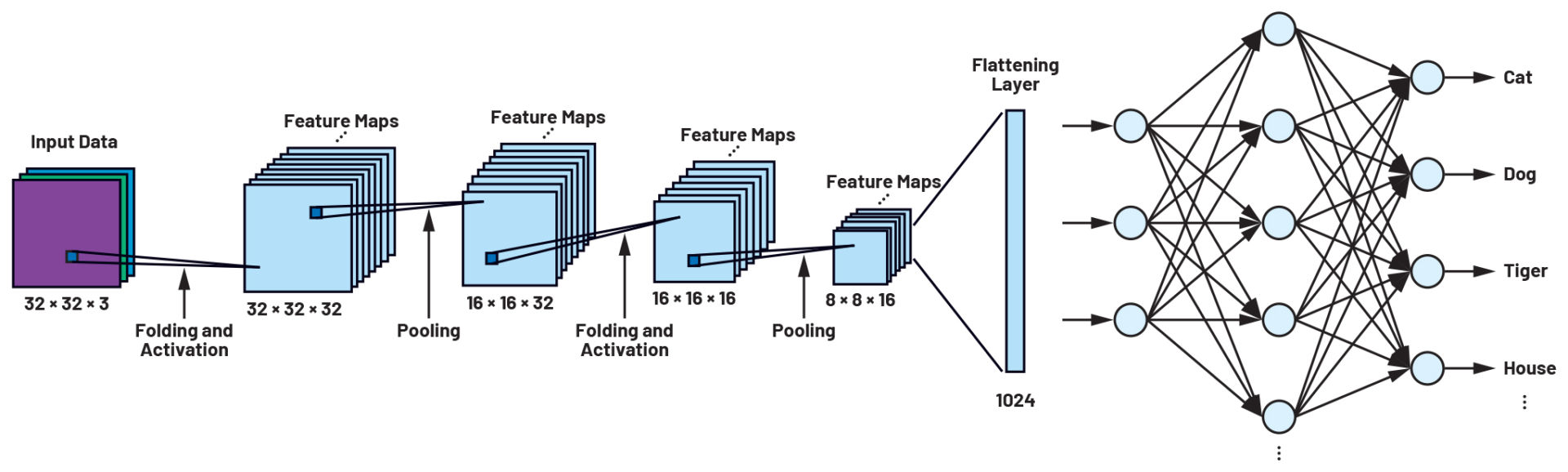
Una rete neurale CIFAR è un tipo di CNN ampiamente utilizzato nei compiti di riconoscimento delle immagini. È composta da due tipi principali di livelli: convoluzionali e di pooling, entrambi utilizzati con grande efficacia nell'addestramento delle reti neurali. Il livello convoluzionale utilizza un'operazione matematica chiamata convoluzione per identificare schemi all'interno di una serie di valori di pixel. La convoluzione avviene nei livelli nascosti, come si può vedere nella Figura 3. Questo processo viene ripetuto più volte fino a quando il risultato desiderato non viene raggiunto. Si noti che il valore di uscita di un'operazione di convoluzione è sempre particolarmente elevato se i due valori di ingresso da confrontare (immagine e filtro, in questo caso) sono simili. Questo valore è chiamato matrice di filtro, nota anche come filtro di kernel o semplicemente filtro. I risultati vengono quindi passati al livello di pooling, che genera una mappa di caratteristiche, una rappresentazione dei dati di ingresso che identifica le caratteristiche importanti. Questa è considerata un'altra matrice di filtro. Dopo l'addestramento, nello stato operativo della rete, queste mappe di caratteristica vengono confrontate con i dati di ingresso. Poiché tali mappe contengono le caratteristiche specifiche della classe di oggetti che vengono confrontate con le immagini di ingresso, l'uscita dei neuroni si attiva solo se i contenuti sono simili. Combinando questi due approcci, la rete CIFAR può essere utilizzata per riconoscere e classificare vari oggetti in un'immagine con un'elevata precisione.
CIFAR-10 è un dataset specifico comunemente utilizzato per l'addestramento delle reti neurali CIFAR. È costituito da 60.000 immagini a colori 32×32 suddivise in 10 classi, raccolte da varie fonti come pagine web, newsgroup e collezioni di immagini personali. Ogni classe ha 6.000 immagini divise equamente tra i set di addestramento, test e convalida, il che la rende ideale per testare nuove architetture di computer vision e altri modelli di Machine Learning.
La differenza principale tra le reti neurali convoluzionali e altri tipi di reti è il modo in cui si elaborano i dati. Attraverso il filtraggio, i dati in ingresso vengono esaminati in successione per le loro proprietà. Con l'aumentare del numero di livelli convoluzionali collegati in serie, aumenta anche il livello di dettaglio che può essere riconosciuto. Il processo inizia con le proprietà semplici dell'oggetto, come bordi o punti, dopo la prima convoluzione e passa a strutture dettagliate, come angoli, cerchi, rettangoli e così via, dopo la seconda convoluzione. Dopo la terza convoluzione, le caratteristiche rappresentano schemi complessi che assomigliano a parti di oggetti nelle immagini e che di solito sono unici per una determinata classe di oggetti. Nel nostro esempio iniziale, si tratta dei baffi o delle orecchie di un gatto. La visualizzazione delle mappe di caratteristica, come si può vedere nella Figura 4, non è necessaria per l'applicazione stessa, ma aiuta a comprendere la convoluzione.

Anche le reti più piccole, come quella di CIFAR, sono composte da centinaia di neuroni per ogni livello e da molti livelli collegati in serie. Il numero di pesi e bias necessari cresce rapidamente con l'aumentare della complessità e delle dimensioni della rete. Nell'esempio di CIFAR-10 illustrato nella Figura 3, ci sono già 200.000 parametri che richiedono una serie determinata di valori durante il processo di addestramento. Le mappe di caratteristiche possono essere ulteriormente elaborate con livelli di pooling che riducono il numero di parametri da addestrare, pur conservando informazioni importanti.
Come accennato, dopo ogni convoluzione in una CNN si verifica frequentemente un pooling, spesso indicato in letteratura anche come sotto-campionamento. Questo passaggio serve a ridurre la mole dei dati. Se si osservano le mappe di caratteristiche nella Figura 4, si nota che le grandi regioni contengono poche o nessuna informazione significativa. Questo perché gli oggetti non costituiscono l'intera immagine, ma solo una piccola parte di essa. La parte restante dell'immagine non viene utilizzata in questa mappa di caratteristiche e quindi non è rilevante per la classificazione. In un livello di pooling, vengono specificati sia il tipo (massimo o medio) sia la dimensione della matrice della finestra. Quest' ultima viene spostata in modo graduale sui dati di input durante il processo di pooling. Nel pooling massimo, ad esempio, viene preso il valore più grande della finestra. Tutti gli altri valori vengono scartati. In questo modo, i dati vengono continuamente ridotti di numero e alla fine formano, insieme alle convoluzioni, le proprietà uniche della rispettiva classe di oggetti.
Tuttavia, il risultato di questi gruppi di convoluzione e raggruppamento è un gran numero di matrici bidimensionali. Per raggiungere il nostro obiettivo di classificazione, convertiamo i dati bidimensionali in un lungo vettore monodimensionale. La conversione avviene nel cosiddetto livello di appiattimento, seguito da uno o due livelli completamente connessi. I neuroni degli ultimi due livelli sono simili alla struttura mostrata nella Figura 2. L'ultimo livello della nostra rete neurale ha tante uscite quante sono le classi da distinguere. Inoltre, nell'ultimo livello, i dati vengono normalizzati per ottenere una distribuzione di probabilità (97,5% gatto, 2,1% leopardo, 0,4% tigre, ecc.).
Questo conclude la modellizzazione della nostra rete neurale. Tuttavia, i pesi e i contenuti delle matrici dikernel e filtro sono ancora sconosciuti e per far sì che il modello funzioni correttamente devono essere determinati attraverso l'addestramento della rete. Questo aspetto sarà descritto nell'articolo successivo, "Addestramento delle reti neurali convoluzionali: Cos'è il Machine Learning? - Parte 2". La terza parte descriverà l'implementazione hardware della rete neurale di cui abbiamo parlato (per il riconoscimento dei gatti, come esempio). A tale scopo, utilizzeremo il microcontrollore di intelligenza artificiale MAX78000con un acceleratore CNN basato su hardware sviluppato da Analog Devices.
[1] In genere si utilizzano le funzioni sigmoide, tanh o ReLU.
[2] ReLU: unità lineare rettificata (Rectified Linear Unit). I valori di ingresso negativi per questa funzione vengono emessi come zero e i valori maggiori di zero con i rispettivi valori di ingresso.







{kind=link}